منابع مقالات معتبر بین المللی
پروژه - فرمت وردمنابع مقالات معتبر بین المللی
پروژه - فرمت وردمقاله در باره ی کشور نروژ…
کشور نروژ
مقدمه
کشور نروژ در نیم کرهٔ شرقی، نیم کرهٔ شمالى قرار دارد. این کشور، میان ۵۸ و ۷۵ درجهٔ عرض شمالى و ۴ درجهٔ طول شرقى واقع شده است.
در قرون هفتم و هشتم میلادی، اقوام نورماند ساکن نروژ به انگلستان و فرانسه حمله کردند و متصرفات وسیعى در این کشور بدست آوردند از سال ۸۷۲ میلادی، حکومت پادشاهى در نروژ روى کار آمد و در قرن ۱۱، دین مسیح در این کشور رواج یافت. در قرن سیزدهم، همزمان با توسعه دریانوردى نروژ، مردم این کشور نیز به اوج قدرت خود رسیدند.
قانون اساسى نروژ در ۱۷ مِى ۱۸۱۴ به تصویب رسید. طبق این قانون کشور پادشاهى نروژ، کشورى آزاد، مستقل، تجزیه ناپذیر و غیرقابل انتقال است و شکل حکومت آن مشروطه سلطنتى و موروثى مى باشد
از بُعد اقتصادی، نروژ در بخش هاى نفت، کشتیرانى و شیلات از موقعیت خاصى در جهان برخوردار است خاصه از نظر نفت در اروپا اهمیت قابل توجهى دارد.

مطالب مرتبط
یکپارچه سازی داده های استخراجی به منظور ایجاد پایگاه داده منسجم و پایدار…
- عنوان لاتین مقاله: Integration of the extracted data to produce a consistent and coherent database
- عنوان فارسی مقاله: یکپارچه سازی داده های استخراجی به منظور ایجاد پایگاه داده منسجم و پایدار.
- دسته: فناوری اطلاعات و کامپیوتر
- فرمت فایل ترجمه شده: WORD (قابل ویرایش)
- تعداد صفحات فایل ترجمه شده: 40
- ترجمه سلیس و روان مقاله آماده خرید است.
خلاصه
ما به بررسی استخراج داده از صفحات وب می پردازیم. داده های استخراج شده در جداول قرار داده می شود. برای کاربرد، به هر حال، برای کاربرد آن، کافی نیست تا داده ها را تنها از یک سایت خاص استخراج کنیم. درعوض داده های حاصل شده از تعداد زیادی از سایت ها به منظور ایجاد خدمات ارزش افزوده گرداوری می گردد. در چنین مواردی استخراج تنها بخشی از داستان می باشد. بخش دیگر یکپارچه سازی داده استخراج شده به منظور ایجاد پایگاه داده منسجم و پایدار می باشد، زیرا سایت های مختلف معمولا از فرمت های دادهای متفاوتی استفاده می کند. به طور تجربی، یکپارچه سازی به معنی انطباق ستون ها در جداول داده مختلف می باشد که حاوی انواع مشابهی از اطلاعات می باشند (به عنوان مثال نام محصول) و منطبق با ارزش هایی می باشند که از نقطه نظر معنایی مشابه بوده اما در وب سایت های مختلف به طور متفاوتی نشان داده می شوند (برای نمونه کوک و کوکاکولا). متاسفانه پژوهش های یکپارچه محدودی تا به حال در این زمینه خاص انجام شده است. بسیاری از تحقیقات مربوط به یکپارچه سازی داده های وب تمرکزش را نبر روی یکپارچه سازی رابط های پرس و جوی وب قرار داده است. این مقاله دارای چندین بخش در مورد با یکپارچگی داده می باشد. به هر حال بسیاری از ایده های توسعه یافته برای یکپارچه سازی داده های استخراجی کاربردی می باشند زیرا مسائل مشابه می باشند.
رابط پرس و جو وب برای تنظیم جستجوها به منظور بازیابی داده مورد نیاز از پایگاه داده وب مورد استفاده قرار می گیرد (که به نام مرکز وب می باشد) شکل 10.1، دو رابط جستجوگر را از دو سایت مسافرتی expedia.com و vacation.com نشان می دهد. کاربری که قصد خرید بلیط هواپیما را دارد معمولا به سایت های زیادی سر می زند تا ارزان ترین بلیط را پیدا کند. با توجه به تعداد زیادی از سایت های پیشنهادی، فرد می بایست به هر کدام بطور جداگانه دسترسی داشته تا بهترین قیمت را پیدا کند، که کار خسته کننده ای می باشد. برای کاهش دادن تلاش فیزیکی، می توانیم رابط های جستجوگر جهانی را ایجاد کنیم که دسترسی یکپارچه ای را به منابع وابسته مختلف امکان پذیر می کند. به این ترتیب کاربر می تواند نیازمندی های خود را در این رابط سراسری مجزا تکمیل کرده و تمام منابع مورد نظر (پایگاه داده ای) به صورت اتوماتیک پر شده و جستجو می گردد. نتایج حاصل شده از منابع مختلف همچنین نیاز به یکپارچه سازی دارند. اما مشکلات یکپارچه سازی، یعنی، یکپارچه سازی رابط جستجوگر و یکپارچه سازی نتایج حاصله، به دلیل غیریکنواختی وب سایت ها چالش انگیز می باشد.
به طور مشخص، یکپارچه سازی تنها مختص به وب نمی باشد. این درواقع، ابتدا در زمینه پایگاه داده مرتبط و انبارهای داده مورد بررسی قرار می گیرد. از این رو، این فصل در ابتدا به معرفی اکثر مفاهیم یکپارچه مرتبط با استفاده از مدل های داده سنتی (برای نمونه، رابطه ای) پرداخته و سپس نشان می دهد چگونه این مفاهیم متناسب با کاربردهای وب بوده و چگونه مشکلات خاص وب مدیریت می گردد.
- فرمت: zip
- حجم: 1.33 مگابایت
- شماره ثبت: 411
مطالب مرتبط
پروژه بررسی انواع و کاربرد سیستم های بارکدینگ…
- پایان نامه جهت اخذ درجه کارشناسی
- عنوان کامل: پروژه بررسی انواع و کاربرد سیستم های بارکدینگ
- دسته: کامپیوتر
- فرمت فایل: WORD (قابل ویرایش)
- تعداد صفحات پروژه: 97
مقدمه
امروزه سیستمهای اطلاعاتی کامپیوتری سهم بسزایی درکارایی امور تجاری و کنترلی دارند. لذا برای حصول این کارایی ضروری است که اطلاعاتی که به کامپیوترها وارد می شوند، دقیق و بهنگام بوده و در ضمن، گردآوری آنها نیز هزینه زیادی دربر نداشته باشد. درمیان انواع سیستمهای شناسایی خودکار، تکنولوژی بارکد جزء ساده ترین ها است. این سیستم به صورت تجهیزات جانبی کامپیوترهای شخصی که امروزه در واحدهای صنعتی، تجاری و اداری کشور جایگاه مهمی یافته اند، قابل بکارگیری است. در این تحقیق سعی شده انواع سیستم های بارکدینگ معرفی شده و کاربرد های هر یک مورد بررسی قرار گیرند.
همچنین باتوجه به پیشرفت روز افزون علوم مختلف، وتوسعه تغییرات در تکنولوژی های موجود، ما را بر آن داشت تا از فنآوری های جایگزین و جدید نیزمواردی را بیان کنیم.
- فرمت: zip
- حجم: 0.36 مگابایت
- شماره ثبت: 505
مطالب مرتبط
ترجمه مقاله یک مدل داده کاوی برای حفاظت خط انتقال مبتنی بر ادوات FACTS…
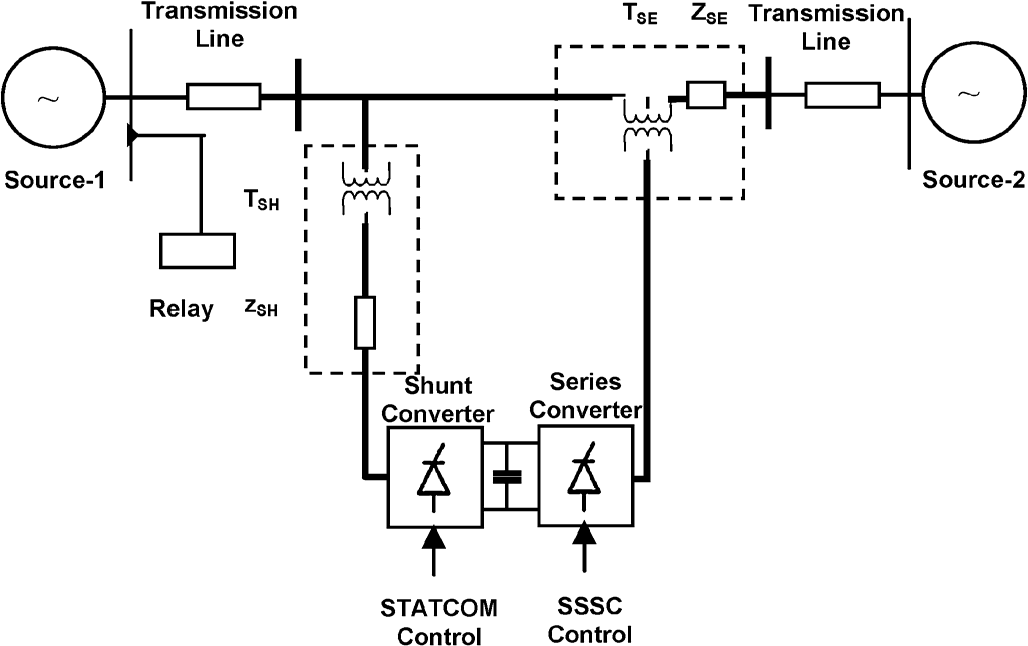 دسته: برق
دسته: برق
حجم فایل: 1451 کیلوبایت
تعداد صفحه: 12
یک مدل دادهکاوی برای حفاظت خط انتقال مبتنی بر ادوات FACTS+ نسخه انگلیسی
A Data-Mining Model for Protection of FACTS-Based Transmission Line
چکیده- این مقاله یک مدل دادهکاوی برای شناسائی ناحیه خطای یک خط انتقال مبتنی بر سیستمهای انتقال ac انعطافپذیر (FACTS) ارائه میکند که شامل جبرانساز سری کنترلشده با تریستور (TCSC) و کنترلر یکپارچه عبور توان (UPFC) است، و از مجموعه درختان تصمیم استفاده میکند. با تصادفی بودن مجموعه درختان تصمیم در مدل جنگلهای تصادفی، تصمیم موثر برای شناسائی ناحیه خطا حاصل میشود. نمونههای جریان و ولتاژ نیم سیکل پس از لحظه وقوع خطا به عنوان بردار ورودی در برابر خروجی هدف “1” برای خطای پس از TCSC/UPFC و “1-” برای خطای قبل از TCSC/UPFC، برای شناسائی ناحیه خطا به کار میرود. این الگوریتم روی دادههای خطای شبیهسازی شده با تغییرات وسیع در پارامترهای عملکردی شبکه قدرت منجمله شرایط نویزی تست شده است و معیار قابلیت اطمینان 99% با پاسخ زمانی سریع بدست آمده است (سه چهارم سیکل پس از لحظه خطا). نتایج روش ارائه شده به کمک مدل جنگلهای تصادفی نشان دهنده تخیص قابل اعتماد ناحیه خطا در خطوط انتقال مبنی بر FACTS است.
عبارات کلیدی- رله دیستانس، تشخیص ناحیه خطا، جنگلهای تصادفی (RF ها) ، ماشین بردار پایه (SVM) ، جبرانسازی سری کنترلشده با تریستور (TCSC) ، کنترلر یکپارچه عبور توان (UPFC).
مطالب مرتبط
معماری پایگاه داده (Database)…
- عنوان لاتین مقاله: Database architecture
- عنوان فارسی مقاله: معماری پایگاه داده
- دسته: کامپیوتر و فناوری اطلاعات
- فرمت فایل ترجمه شده: WORD (قابل ویرایش)
- تعداد صفحات فایل ترجمه شده: 11
- ترجمه سلیس و روان مقاله آماده خرید است.
خلاصه
ما هم اکنون در شرایطی قرار داریم می توانیم تصویر مجزایی از بخش های مختلف سیستم پایگاه داده و ارتباطات میان آن ها مورد بررسی قرار دهیم.
معماری سیستم پایگاه داده تا حد زیادی تحت تاثیر سیستم های کامپیوتری مشخصی می باشد که در آن ها سیستم پایگاه داده به اجرا در می آید. سیستم های پایگاه داده می تواند بصورت متمرکز یا سرور-کلاینت بوده که یک دستگاه سرور به اجرای فعالیت به نیابت از دستگاه های کلاینت چندگانه می پردازد. سیستم های پایگاه داده همچنین می تواند برای بهره برداری از معماری کامپیوتر پارالل طراحی گردد. پایگاه های داده توزیع شده، تجهیزات مجزای جغرافیایی چندگانه را تحت پوشش قرار می دهد.
- فرمت: zip
- حجم: 0.61 مگابایت
- شماره ثبت: 411